Artificial intelligence is not a substitute for human intelligence; it is a tool to amplify human creativity and ingenuity
How is image,video perceived by AI?
Ever wondered how a single prompt can bring a full video to life? AI is turning imagination into motion and it’s happening faster than we think.The world of content creation is undergoing a massive transformation driven by Artificial Intelligence (AI). Before we explore the inner workings of an AI video generator, it is crucial to have a basic understanding of artificial intelligence as a whole. At their core, AI videos are deep learning models trained on vast datasets of images, videos, and text. They just don’t copy the results but even understand patterns, timing, and context. For this, we use multiple models like GANs and Diffusion Models, which we will study in detail later. These help us create images that, with the help of the study of the change of pixels over frames, help us create videos.
Models For Image And Video Generation
1)Generative Adversial Networks(GAN’s)
Generative Adversarial Networks use two networks, Generators and Discriminators, which are both trained independently. The purpose of the generator is to create images, while that of the discriminator is to calculate the accuracy of the images and generate a loss value.
So, initially, we feed a random normalized distribution to the generator, which uses a transported convolution layer to increase spatial dimensions and resolution and creates a sample image. This sample image is then fed to the discriminator, which calculates the loss function using the formula :

It measures the log-likelihood of correctly classifying real data (logD(x)) while simultaneously measuring the log-likelihood of correctly rejecting fake generated data (log(1−D(G(z)))). Maximizing this expression forces the discriminator to become an accurate binary classifier, distinguishing the true data distribution from the generated distribution.
This loss is ideally 1 for real images and 0 for fake images. Similarly, even the generator function has a loss, and the end goal is to minimize the generator loss and maximize the discriminator loss. Once the losses are calculated, we use back propagation, the gradient of the loss function, and set the gradient to zero to change weights and biases via the discriminator as parameters for the generator function. The discriminator acts as a guide to help the generator learn and evolve!
2)Diffusion Models
Diffusion models are generative models that create new data by starting with random noise and gradually making something meaningful. The process involves slowly corrupting the data by noise during training and learning to reverse this process.
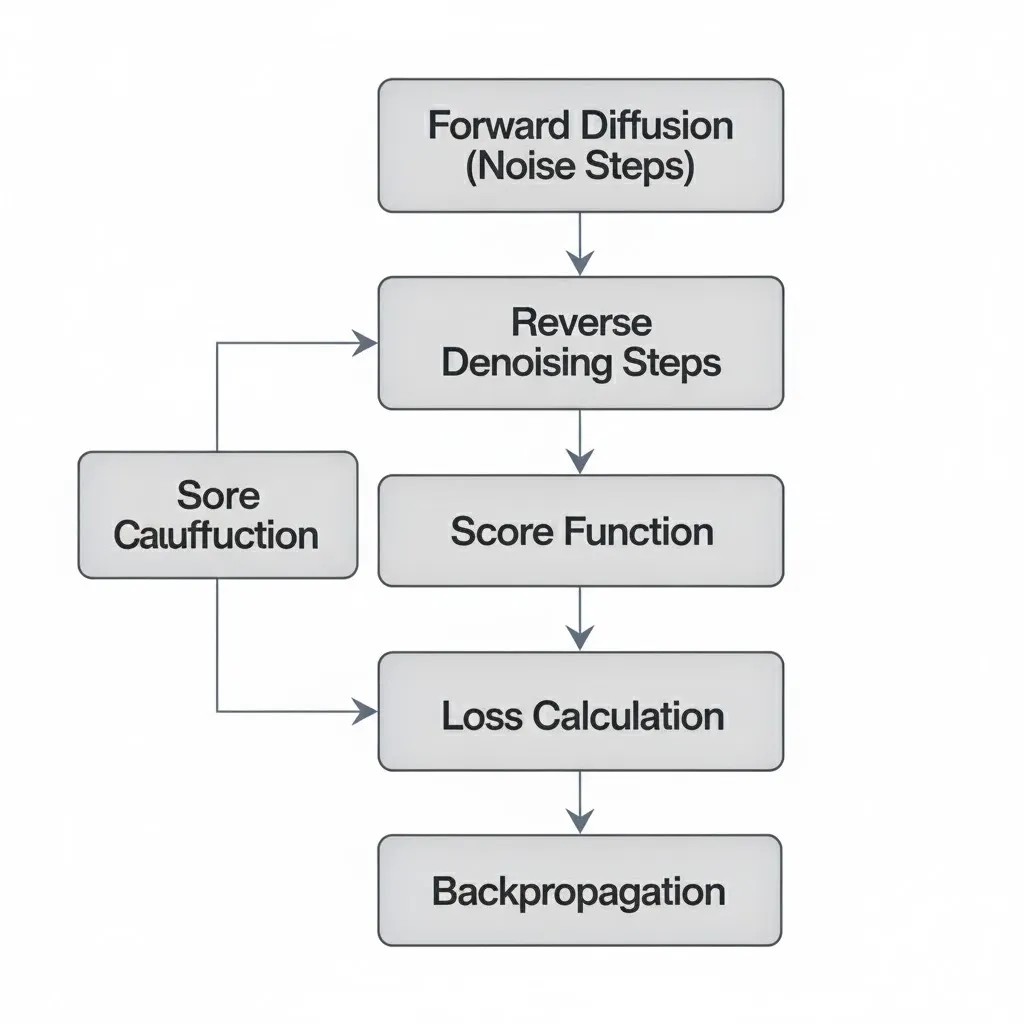
There are three components of the process.
1)Forward Diffusion: This process involves adding noise to the data in a series of small steps. Each step involves a small incremental step of increasing the noise and making the data more random until it resembles pure noise.

The abouve equation defines the incremental step of adding noise to an image in a Diffusion Model. It says the next noisy version (xt) is sampled from a Normal Distribution whose mean slightly retains the old image (xt−1) and whose variance (βt) controls the amount of Gaussian noise added.
2)Reverse Diffusion Process: This aims to construct the original data from the noisy data by slowly using neural networks using conditional probability.

This equation defines the denoising step, where the model learns to gradually reverse the noise by estimating a slightly cleaner version (μϕ) from the current noisy data (xt). It uses a learned Normal Distribution to transition from pure noise back to a clear image.
3)Score Function: It measures the difference between the predicted and actual noise. The loss function is calculated at the denoising step and minimized simultaneously using conditional probability.

The image shows the mathematical definition of the Score Function (sϕ), which is a neural network trained to approximate the gradient of the log-probability (∇xtlogq(xt)) of the noisy data distribution at timestep t. This gradient vector essentially points in the direction that maximizes the likelihood of the noisy sample belonging to the overall data distribution, guiding the model during the denoising process.
Comparison between models for optimized AI content generation
1)The GAN framework
Pros: i)Strong ability to generate high-quality, realistic images, videos, and voice recordings. ii)Specifically helpful for image enhancements and content creation iii)Pattern Discovery without labeled data
Cons: i)Requires substantial computational resources ii)The realism of content can be used for creating deepfakes iii) Less Diversity of data
2)Diffusion Model
Pros: i)Creates images with diversity ii) Enables fine control and prompt-based customization iii)More stable training
Cons: i)Difficult to train from scratch ii)Slow inference iii)Requires high memory and computational power
Conclusion
Use GANs for image synthesis, image-to-image generation, and fast inference, whereas use diffusion models for text-to-image generation, filling missing image parts, or places where accuracy matters!

Applications In The Education Industry As AI advances, it has started revolutionizing the education industry in powerful ways, right from personalized education to content creation.
Content Creation: Generative AI excels at creating new teaching materials, such as questions for quizzes, exercises, or summaries of concepts. Using AI, it is possible to create video summaries of notes and visualizations of workflows using images.
Teaching Assistant: We can have a bot designed for a particular college, which can help to get doubts solved instantly.
Personalized Learning: AI can help us design courses tailored to personalized interests and help us design an academic curriculum with the latest skillsets required in the industry.
Gamified Learning and Assessment: Making games that help students learn and interactively assess themselves would be more engaging.
FAQ’s
Q1)A detailed prompting guideline for a Layperson!
Prompting isn’t just typing what you want. It’s about structuring your intent in a way the model understands Here is a structured step-by-step guide for the same:
1)Start with a clear intent: Make a clear picture in your mind first, and don’t write anything vague
2)Structure your Prompt: [Subject] + [Action/Scene] + [Style] + [Lighting/Mood] + [Details/Camera settings or Composition] + [Medium/Artist reference]
3)Add visual and technical details: Add details like lighting, background, composition, texture, and camera terms
4)For Video Prompts: Add motion cues, continuity hints, duration, and framing
5)Use style anchors, and use negative prompts og what not to make too!
Pro Tip: Start broad, then refine details with subsequent prompts one by one (PS: Asking multiple changes together causes inaccuracy!)
Q2)How can AI video creation revolutionize the content creation industry?
Nowadays, there are AI available which can convert blogs into an AI. This has led to a lot of influencers rising solely based on AI-generated content with their face and voice.AI’s advancement has helped us to get video scripts with lip sync, making it impossible to differentiate from original content.
It has even revolutionized the ad industry by creating ads that used to cost lakhs of rupees and weeks to make, just by a prompt for a negligible cost, and that too of utmost quality, with everything being editable by just a prompt.
Q3)How does AI read pictures we upload?
1)The first step involves converting the images to a grid of pixel values, with each pixel being assigned an RGB value between 0 and 255.
2)The AI then passes the data through layers that detect features, patterns, and complex structures like faces, objects, or emotions.
3)The image then gets compressed to a feature vector, a complex representation of what the model understands about the image.
- Interpretation of the objects, segmentations, image captioning, and visual image reasoning.
5)Models like Gemini and GPT-4 use transformers to align image features with text, enabling “reading of visual scenes”
Future Of AI Video Generation
In the future, AI will become your co-director, animator, and storyteller, turning imagination into moving reality. Current diffusion models require hundreds of denoising steps and are very compute-heavy, so the breakthrough comes with flow matching by building more efficient models, building hybrid models like combining GANs with Diffusion, enabling real-time generation. Spatio Temporal Attention, which expands the transformer architecture to handle 3D via temporal token compression. Another innovation could be 4D models, which capture objects and images together and understand spatial geometry. Generating visuals matching a soundtrack with pose and depth guidance and reusing past frame embeddings to maintain continuity.
“Tomorrow’s creators won’t just edit videos ,they’ll converse with them.”